Opus 4.6 v Qwen3.6-35B-A3B
This table has been showing up on my feeds for a few days.
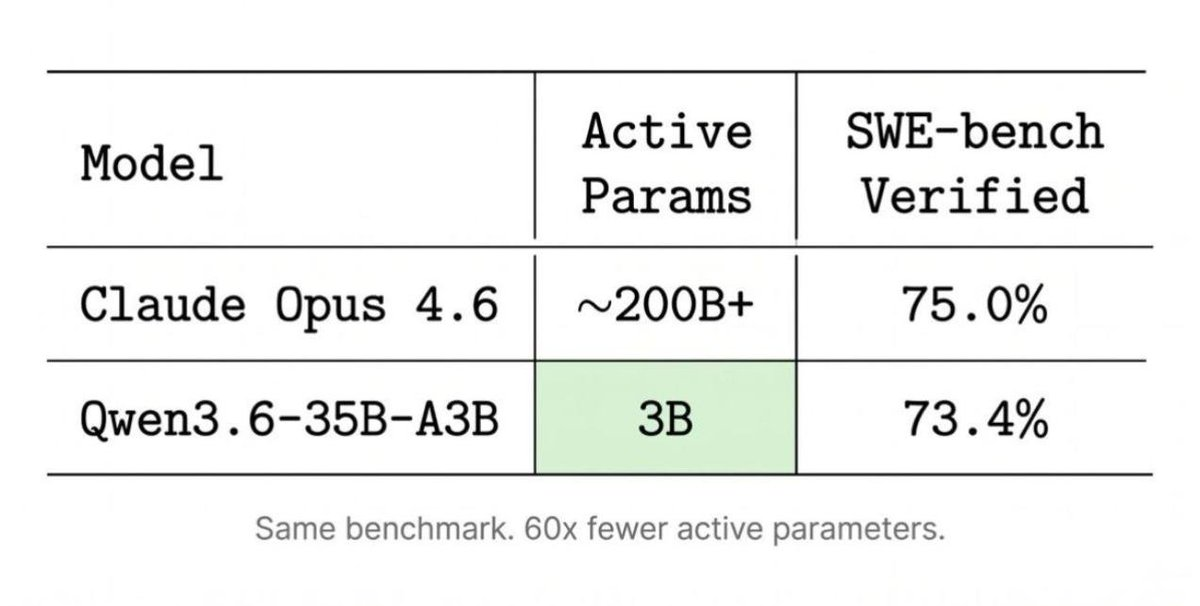
Then someone sent it to me and asked, basically, "so the gap is gone, right?"
No. Two reasons.
The problem is two-fold: with the benchmark, and with the model.
The benchmark first. SWE-bench has been around for a while. Everyone trying to beat it kind of knows what's in there. So they bring their own intelligence - personal meat, or AI brain - and aim at the solutions with the best chance of moving the number. That's target distillation. The benchmark isn't solved, sure, but those gradual better results aren't a sign of catching up. They're a sign of the benchmark being stale. The opposite of fresh. Stick a dart target on a wall, throw tons of darts at it for long enough, and occasionally one lands closer than the ones before. That's not better aim. That's just darts and time.
Now the model. Any model can be good at a thing. If that's the goal of the model, then great, that's a success. A narrowly scoped model is better for a narrowly scoped problem, because it usually needs fewer resources. And that's what the image does: it takes an extremely general model with extreme capabilities and a small coding-focused model, and puts them on one narrow task.
The way it reads to me: Opus is better than Qwen, but not by much, and once you count params Qwen is hugely more efficient. Which is true. Through a very narrow lens.
And the lens is even narrower than it looks. The highlight is on active params. It's a MoE model next to a dense one, so it quietly ignores the params you actually need to store the thing. It might as well add a latency column and let Qwen win that one too. None of it is wrong. It's just a careful choice of which columns to show.
And the table can't show any of this. Even if the difference is as tiny as it claims, I'd bet you can survive a whole day coding with Opus 4.6, and you'd give up on Qwen3.6 after ten minutes. A score is one point. A day of real work - context, recovering from mistakes, knowing when it's lost - is a whole distribution the score never sees.
We've seen this from the other side too. A year ago coding with Opus 4.1 was already a great experience, and that wasn't anywhere near today's SWE-bench number. The score climbed a lot. The experience didn't, by the same proportion, because it was already good.
None of this is me dunking on small models. I'm a fan, and I want to make them work. I'm looking forward to trying out different local models, especially because I'd love to get terminal-agent running nicely with local ones. So this isn't "Qwen is bad." It's "don't read this table as the gap being closed." Read it as one narrow column, picked carefully, on a benchmark that's had a long time to be studied.